Onglet périmètre
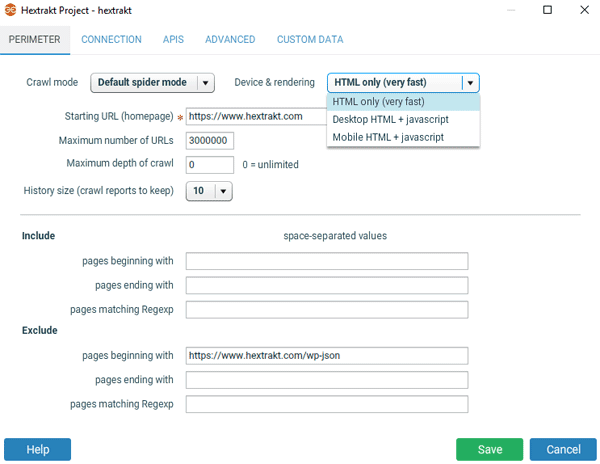
Mode de crawl
Default spider mode :
le mode spider par défaut crawle en suivant les liens, redirections, etc., présents dans les pages, c'est le mode recommandé pour crawler un site. Vous obtiendrez de cette façon des rapports de crawl complets, notamment concernant le maillage interne.
List of URLs :
Pour des besoins spécifiques ou des vérifications supplémentaires, vous pouvez coller une liste d'URLs en sélectionnant "list of URLs".
Device & rendering
HTML only est le réglage par défaut à utiliser le plus souvent. Les crawls sont très rapides.
Javascript : pourquoi crawler en mode HTML+Javascript ?
- pour crawler des sites construits avec un framework javascript,
- pour récupérer des données supplémentaires dans les pages en scrapant avec XPath, CSS path ou des expressions régulières,
- pour crawler comme Googlebot pour smartphone ou réaliser un audit SEO comparatif mobile vs. desktop,
- pour avoir plus d'indicateurs de performance de chargement des pages (DOM content loaded...),
- pour récupérer des données présentes dans le DOM mais pas dans le code source HTML
Un crawl en mode de rendu javascript est plus long qu'un crawl HTML only ; pour les sites qui n'utilisent pas de Javascript pour afficher les contenus il est recommandé d'utiliser le mode HTML par défaut, sauf pour des besoins spécifiques tels que décrits ci-dessus.
Remarque : quand vous crawlez en mode de rendu javascript, ne fermez pas la fenêtre du navigateur slimjet. Lors d'un crawl mobile, n'ouvrez pas la fenêtre du navigateur en grand. En mode JS Hextrakt récupère aussi les breadbcrumbs correctement structurés (schema.org ou datavocabulary.org).
Autres réglages
L'URL de départ (starting URL) est en général la page d'accueil. Nous recommandons de faire un crawl complet (au moins lors du premier crawl) sans limiter la profondeur de crawl ni le nombre de pages. Vous pourriez passer à côté de problèmes à corriger.
Pour inclure d'autres domaines ou sous-domaines, il suffit de les ajouter dans le champ "URLs beginning with" en les séparant par un espace, par exemple http://www.mydomain.com http://www.mydomain.fr http://www.mydomain.co.uk http://blog.mydomain.com. Vous indiquez ici tous les domaines que vous souhaitez crawler, y compris le domaine de l'URL de départ.
Inutile de remplir ce champ s'il n'y a pas d'autres domaines que celui de départ.
Pour crawler tous les sous-domaines en prenant en compte les URLs http et https, utilisez le champ "URLs matching Regexp" avec cette expression régulière :
(http|https):\/\/[^\.]*\.
Vous pouvez écrire dans ce champ plusieurs expressions régulières séparées par des espaces, ce qui correspondra à la 1ère expression OU la 2ème expression OU...
Taille de l'historique ("History size") : si vous crawlez des sites volumineux et souhaitez conserver de nombreux rapports de crawl, vérifiez que vous avez suffisament d'espace disque disponible.
Onglet connexion
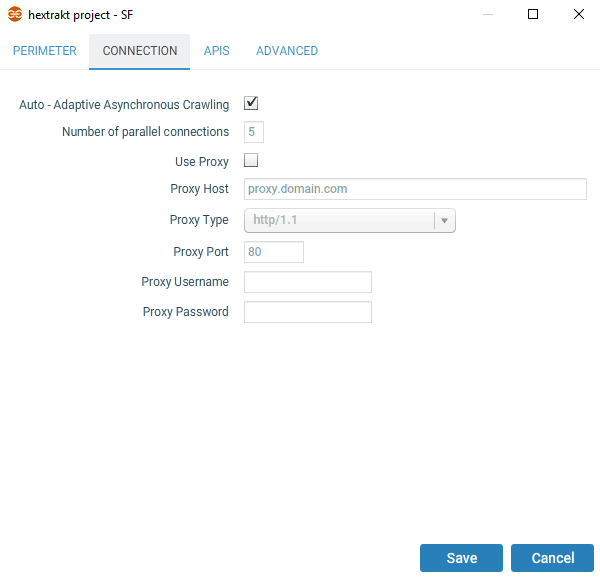
La plupart du temps vous pouvez laisser les réglages par défaut, sauf si vous souhaitez spécifier vous-même le nombre de connexions en parallèle. Le crawl adaptif (disponible uniquement en mode "HTML only") va ajuster automatiquement la vitesse de crawl en fonction des ressources serveur et client ; si vous ne connaissez pas le nombre de connexions parallèles à paramétrer, laissez le champ "Auto - Adaptive Asynchronous Crawling" coché pour éviter de surcharger le serveur.
Remarque : vous ne pouvez crawler un site qu'avec l'accord de son propriétaire.
Onglet APIs
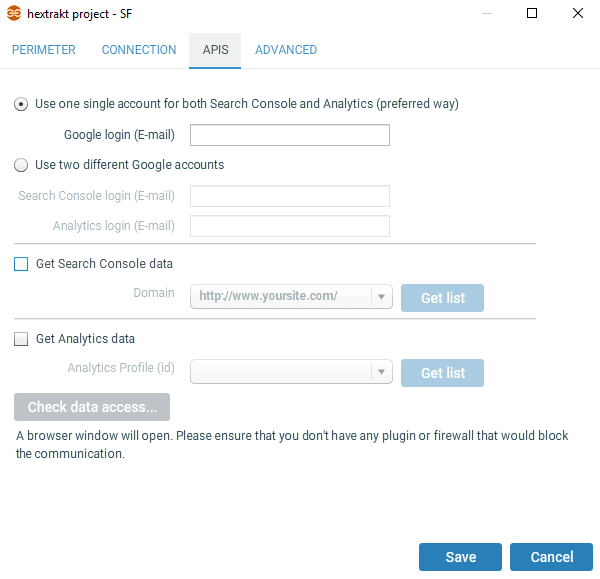
Entrez l'adresse email du compte qui vous permet d'accéder à Google Analytics et Search Console et cochez "Get Search Console data" et "Get Analytics data". Quand vous cliquez sur "Get list", une fenêtre de votre navigateur va s'ouvrir pour connecter Hextrakt à votre compte Google afin de pouvoir accéder en lecture aux données de Google Analytics et Search Console.
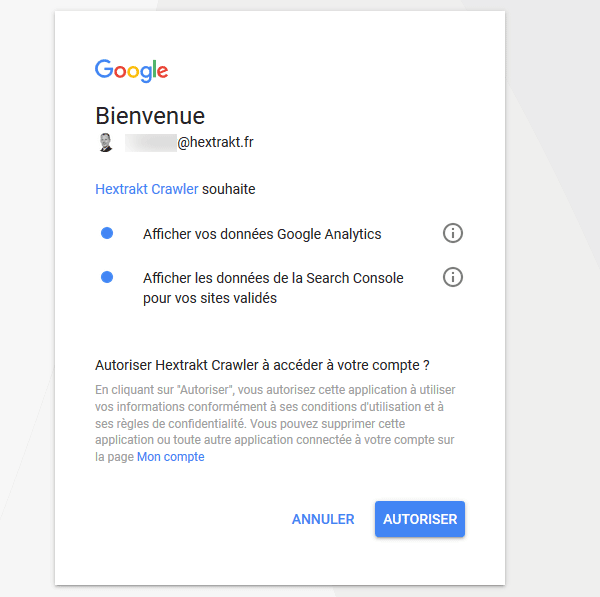
Sélectionnez ensuite le domaine dans la liste des sites Search Console et la vue Google analytics correspondante (habituellement la vue principale). Pour plus d'information sur la structure des comptes, vous pouvez consulter l'aide Google Analytics.
Si vous ne voyez pas dans la liste le site que vous souhaitez crawler, il est possible que le compte (l'email) entré dans le champ "Google login" n'ait pas les droits d'acccès suffisants pour ce site.
Onglet avancé
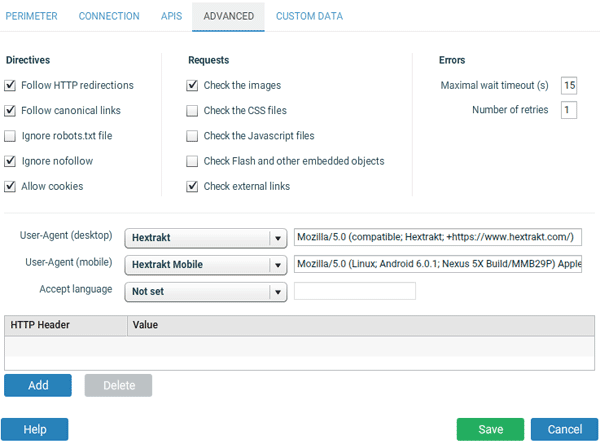
Vous pouvez habituellement laisser les réglages par défaut.
- Ignore robots.txt file : si coché, hextrakt va crawler les pages même si elles sont interdites aux robots. Pour vérifier l'existence de certains conflits (pages avec l'instruction noindex mais bloquées par le fichier robots.txt, dans le menu "Directives" des rapports), vous pouvez cocher cette page.
- Ignore nofollow : si coché, hextrakt va crawler les liens ayant l'attribut nofollow.
- Allow cookies : autorise hextrakt à gérer les cookies.
- Check [...] : si coché, Hextrakt va récupérer le statut (et Content-Length) pour ces URLs.
- Maximal wait timeout : nombre de secondes à attendre avant une réponse http.
- Number of retries : en cas d'erreur réseau, nombre de tentatives supplémentaires.
Données personnalisées
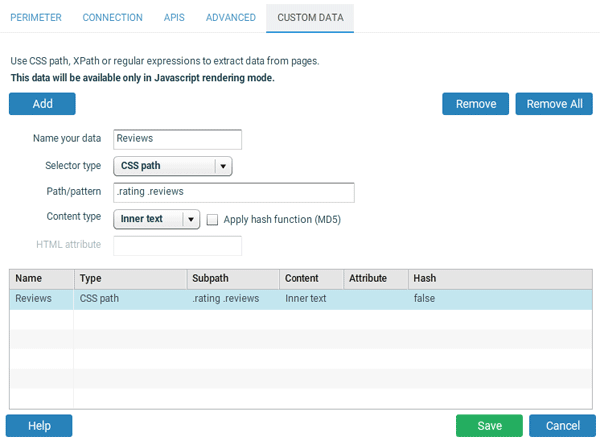
L'extraction de données personnalisées fonctionne uniquement pour les crawls en mode Javascript. Vous pouvez ajouter jusqu'à 10 champs custom pour récupérer des données supplémentaires dans les pages, en utilisant XPath, CSS path ou des expressions régulières.
Pour aller plus loin dans la recherche de contenus dupliqués dans certains éléments HTML (en complément de l'utilisation du hash du contenu de la balise <body> calculé par défaut par Hextrakt), vous pouvez appliquer une fonction de hachage (le hash sera une chaine unique pour toutes les données identiques). Vous pourrez identifier facilement les URLs contenant des éléments dupliqués dans Excel ou OpenOffice.

Pour afficher ces données supplémentaires dans un rapport, utilisez la recherche avancée et ajoutez les colonnes "custom data...".
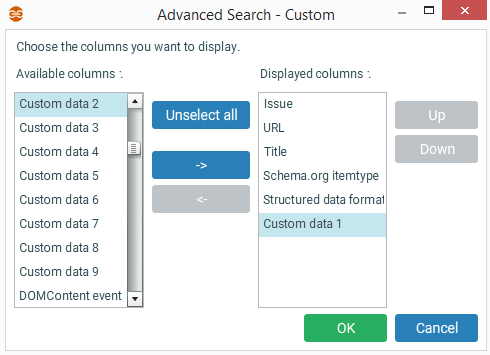
Par exemple pour le crawl d'un site ecommerce, vous pouvez enrichir les données de crawl avec pour chaque fiche produit le nombre d'avis clients :
