Nous présentons ici le déroulé des actions à mettre en oeuvre pour la réalisation d'un audit technique de site web dans le but d'améliorer sa qualité et son référencement naturel.
Les données de crawl croisées avec les données d'usage de Google obtenues grâce à un crawler comme Hextrakt permettent des analyses très pertinentes et constituent la matière première du SEO technique.
L'analyse de logs pour le SEO, qui consiste à croiser les logs de Googlebot (récupérées sur le serveur web) avec les données de crawl, sera abordée dans un prochain article. Il s'agit de techniques d'optimisation avancées, à utiliser principalement pour des sites volumineux (là où les effets peuvent être les plus significatifs), qui viennent en complément d'un audit technique basé sur un crawl.
Un audit technique se déroule en 3 étapes :
- Crawl : le crawler suit les liens pour découvrir toutes les pages du site et en extrait les données utiles au SEO.
- Analyse : les données sont restituées sous forme d'informations dans des tableaux de bord et des indicateurs permettant des analyses plus approfondies, afin d'identifier les points à corriger et les leviers d'optimisation.
- Corrections et optimisations : les erreurs doivent être corrigées en priorité, puis on s'occupe des alertes (warning) et de l'implémentation d'optimisations.
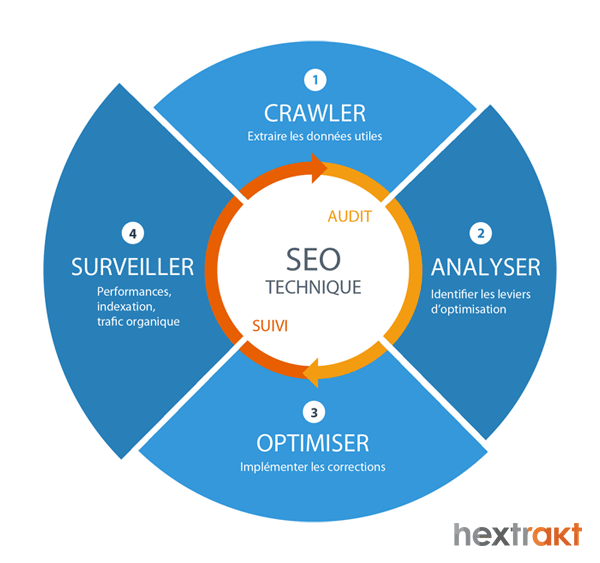
Pour boucler la boucle et visualiser l'ensemble des actions requises - pour la partie technique du référencement naturel, il ne faut pas oublier le suivi indispensable des performances : il s'agit de monitorer les erreurs (erreurs 404, 500...), vérifier la bonne indexation des pages dans Google et le trafic organique (en provenance des moteurs de recherche).
Crawl : configuration et lancement
Le but du crawl est de récupérer les données utiles au SEO sur toutes les pages du site. Pour un premier crawl et sauf cas particuliers (sites construits avec des frameworks Javascript), on réalise un premier crawl exhaustif sans limiter la profondeur ou le nombre d'URLs, en mode "HTML only". Un crawl en mode de rendu Javascript permettra de récupérer plus de données mais sera aussi plus long.
Remarque : le crawl d'un site web utilise des ressources du serveur, proportionnellement à la vitesse de crawl. Hextrakt utilise pour cette raison une technologie de crawl asynchrone adaptif afin de régler automatiquement une vitesse de crawl optimale. Assurez vous d'avoir l'autorisation du propriétaire du site et informez-vous sur le meilleur moment pour crawler (les rapports web analytics peuvent vous y aider).
Connexion aux APIs Google
Hextrakt permet de croiser les données techniques issues du crawl avec les données d'usage en provenance de Google Analytics et Google Search Console afin de réaliser des analyses pertinentes : certaines pages peuvent être inactives (ne reçoivent pas de visites depuis les résultats des moteurs de recherche) ou n'ont pas d'impressions (ne s'affichent pas dans les résultats de recherche).
Si vous avez accès aux comptes Google analytics et/ou Search Console du site que vous crawlez, il est recommandé de configurer la connexion aux API Google, afin d'obtenir des informations plus pertinentes.
Analyses des résultats
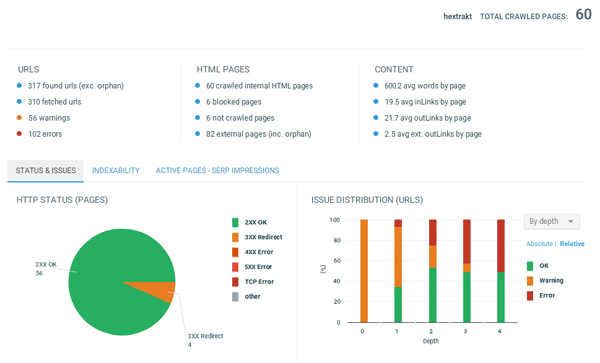
La vue d'ensemble ("Overview") permet de se faire une première idée des erreurs et de leur répartition, des problèmes d'indexabilité (onglet "indexability"), et des ratios de pages actives / inactives, avec impressions / sans impressions.
Segmenter pour donner du sens
Séparer les URLs en différents sous-ensembles significatifs qui ont des caractéristiques communes, permet de comparer, donner du sens, et déterminer plus facilement des relations de causalité.
A moins d'auditer un tout petit site de quelques pages, pour des analyses pertinentes, il est donc recommandé de segmenter les URLs, afin d'étudier les indicateurs par groupes de pages pertinents et de comparer ces groupes entre eux. Une première catégorisation existe par défaut dans hextrakt (comme dans la plupart des crawlers), c'est la catégorisation par niveau (en fonction de la profondeur dans l'arborescence). Votre propre segmentation (templates, thématiques...), en fonction de chaque projet, apportera de nombreuses idées d'optimisation et vous aidera à cibler les fichiers à corriger (templates).
La catégorisation des URLs constitue une bonne pratique à mettre en oeuvre en début d'analyse ; une fois les URLs taguées, elles le restent pour les crawls suivants (seules les nouvelles pages découvertes sont à taguer le cas échéant).
Passer en revue les différents rapports
C'est en forgeant... Quand vous aurez analysé de nombreux rapports de crawl et acquis certains réflexes, il vous sera plus facile de faire des recommandations d'actions correctives. L'expérience aidant, les bonnes idées d'optimisations viennent naturellement.
Parmi les points à vérifier en priorité (mobile et desktop) :
- Le ratio de pages sans impressions est-il important ? Il se peut que certaines pages ne soient pas indexées dans Google. Les pages importantes d'un point de vue SEO doivent être actives (c'est à dire recevoir des visites en provenance des moteurs de recherche).
- Les directives : erreurs dans le fichier robots.txt, les erreurs dans les directives d'indexation (balises noindex) ou dans les balises canonical, les problèmes spécifiques au mobile et aux sites multilingues.
- Les redirections et erreurs (status codes 404, 500, 301) qui peuvent poser problème si elles sont trop nombreuses.
- Les temps de chargement
- La structuration des contenus (title, balises Hn, données structurées), l'accès à ces contenus (profondeur, maillage interne)
- les contenus dupliqués
- ...
La mini-liste ci-dessus peut servir de point de départ. En SEO, y compris technique, il est nécessaire de pousser tous les leviers disponibles... Vous l'aurez compris, on vérifie beaucoup plus de points lors d'un audit complet.
Corrections et optimisations
Cette phase consiste à implémenter les correction ou les faire implémenter, et vérifier qu'elles soient effectives. Un nouveau crawl permet de vérifier que les erreurs ont bien été corrigées (menu "History & changes").
Si celui qui fait les recommandations n'est pas celui qui les implémente effectivement, il devrait accompagner les développeurs pour faciliter leur mise en place. Le but de tout ceci n'est pas de faire un audit, mais d'améliorer le SEO...
Suivi
Un site web évolue en permanence avec l'ajout de nouveaux contenus, de nouvelles fonctionnalités. Il est indispensable de veiller notamment à ce que ces nouveaux contenus soient bien indexés et apportent du trafic organique, que les nouvelles fonctionnalités ne génèrent pas d'erreurs.
Outils :
Google analytics permet de configurer des alertes : par exemple pour recevoir un email en cas de chute de votre trafic organique (visites en provenance des moteurs de recherche).
Google Search Console : le menu Exploration > Erreurs d'exploration permet d'identifier des erreurs au niveau du site (DNS, connectivité du serveur, fichier robots.txt) et des URLs (URLs en erreur). Le menu Exploration > Statistiques sur l'exploration permet d'identifier une chute du nombre de pages explorées ou, au contraire, une augmentation soudaine sans ajout de nouvelles pages (googlebot pourrait gaspiller son budget de crawl sur des URLs inutiles : spider trap).
Hextrakt : des crawls à intervalles réguliers permettent de vérifier l'absence de nouvelles erreurs ou variations dans les données analytics en comparant au crawl précédent. En cas de mise en production de nouvelles fonctionnalités, mises à jour de CMS ou tout changement pouvant impacter le site techniquement, il est fortement recommandé de lancer un crawl.
Quelques liens utiles pour s'initier et se perfectionner au SEO :
Pour aller plus loin, un très bon article sur l'audit SEO